Portfolio
Sampling of Data Science Projects





Interested in machine learning, Bayesian modeling, and functional programming. I use R, Python, and SQL professionally and spend my own time learning new languages.
I am a credentialed actuary with a background in mathematics. Contact me or you can find me on LinkedIn or GitHub.
Distracted driving is one of the leading causes of automobile accidents that can lead to irreplaceable damages. Soteria provides a new way to prevent this risk and introduces a revolutionary end-to-end product.
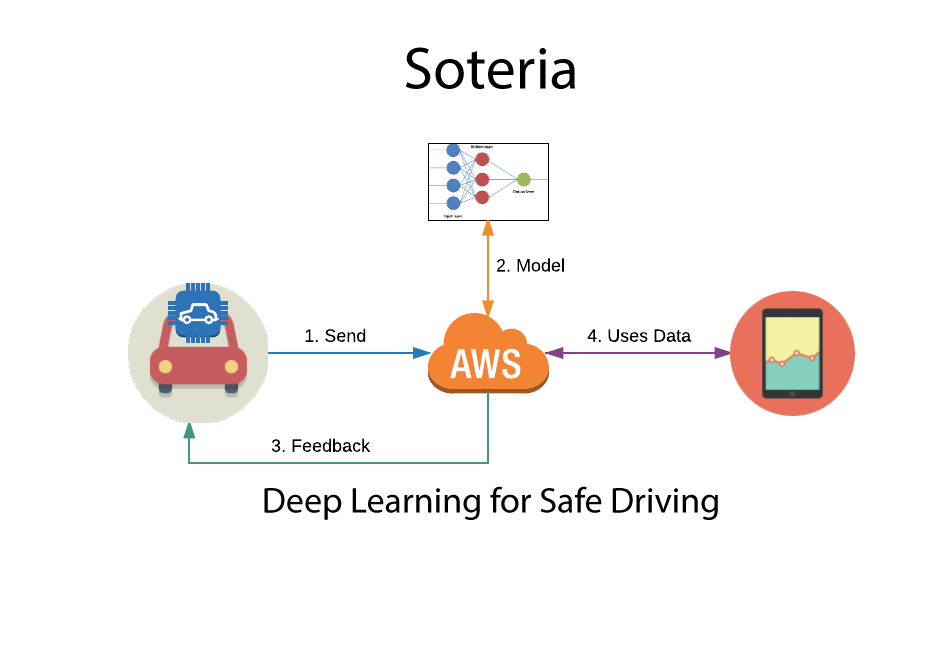
Soteria uses combination of the internet of things (IoT) and machine learning to detect distracted driving. The IoT component consists of a custom Raspberry Pi unit connected to the cloud while the machine learning component is a convolutional neural network (CNN).
The neural network was trained on over 20,000 images from 10 different classes. Classes included safe driving, texting, talking on the phone, operating the radio, drinking, reching behind, talking, and hair/makeup.
The network was based on the popular VGG-16 framework, a 16-layer neural network created by the Visual Geometry Group out of the University of Oxford. With VGG-16 pre-trained weights as a starting point, the model was further trained to learn the idiosyncrasies of our data.
Our model also includes global average pooling (GAP) just before the final output layer which allows the model to localize objects (e.g. identify hands). The benefit of GAP can be seen below in the class activation maps. Note how the model recognizes the hands in the first row of images (safe driving) while it regonizes the phone in the second row of images (texting).






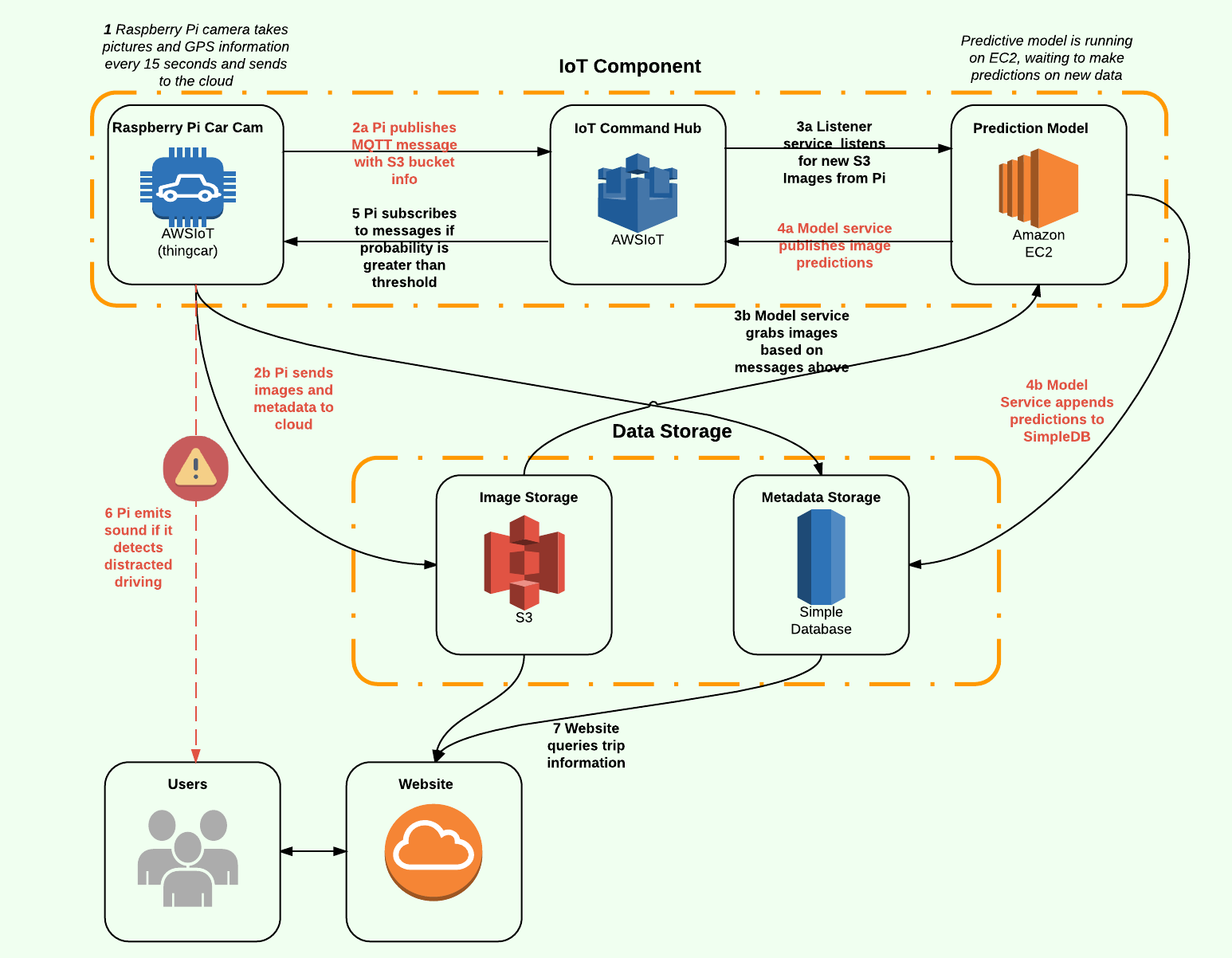
As shown in the video above, Soteria provides users with real-time feedback as it uses deep learning to detect distracted driving. The project architecture below shows how we collect data with a custom Raspberry Pi device, store the data in a NoSQL database, and communicate the data with the user via MQTT message passing. Check out http://soteriasafedriving.com for more detail.

While Craigslist is wonderful for its low cost and ease of use, it is very difficult and time-consuming to use Craigslist as a price comparison tool. This project attempts to filter the massive corpus of Craigslist data into a human-readable summary of prices across various markets over time. We focus on Apple's iPhone in this project but it can easily be extended into other markets as well.
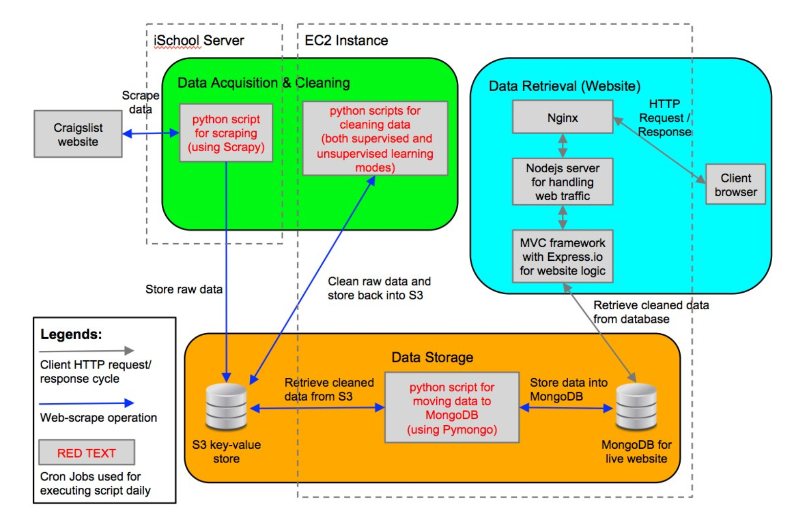
We use a Python script to scrape the iPhone data off of the Craigslist website. The Python script is executed on a daily basis using Cronjob. Raw data from the data acquisition process is stored in Amazon S3’s key-value store. Natural language processing (NLP) techniques are used to match potentially different descriptions to the same item as well as to weed out unrelated items. Cleaned data is again stored in Amazon S3's key-value store.
The supervised learning classification was a two-step process: a machine learning classifier and regular expressions. The initial classification was binary (iPhone/not iPhone) using the Naive Bayes algorithm. Other supervised learning techniques were considered such as Logistic Regression and Support Vector Machines, but the Naive Bayes algorithm was chosen for its simplicity and transparency. The second step in the process is a regular expression waterfall where iPhones are classified based on various text patterns.
The purpose of the unsupervised learning algorithm is to make the classification process scalable once the price comparison tool is expanded to include items beyond the iPhone. In such a case, it would be impractical to conduct supervised learning on each individual item. Unsupervised learning can categorize postings without having to manually train the model.
The web application is a live website where the user can search for a given iPhone in a given location over a specified timeframe. The chosen stack for building the website is commonly known as the “MEAN” stack (MongoDB, Express.io, Angular.js, Node.js). This is a full- stack where the server, database, and model-view-controller (MVC) framework can be setup such that the website can work interactively with MongoDB. Whenever a user queries the website, the “model” component of the MVC framework will send a request to acquire the needed data from the MongoDB database stored on Amazon EC2. The “controller” component of the framework will perform any further calculations and data preparations prior to passing the “view” component of the framework. The user will then be able to see the data in the form of a rendered D3.js visualization.
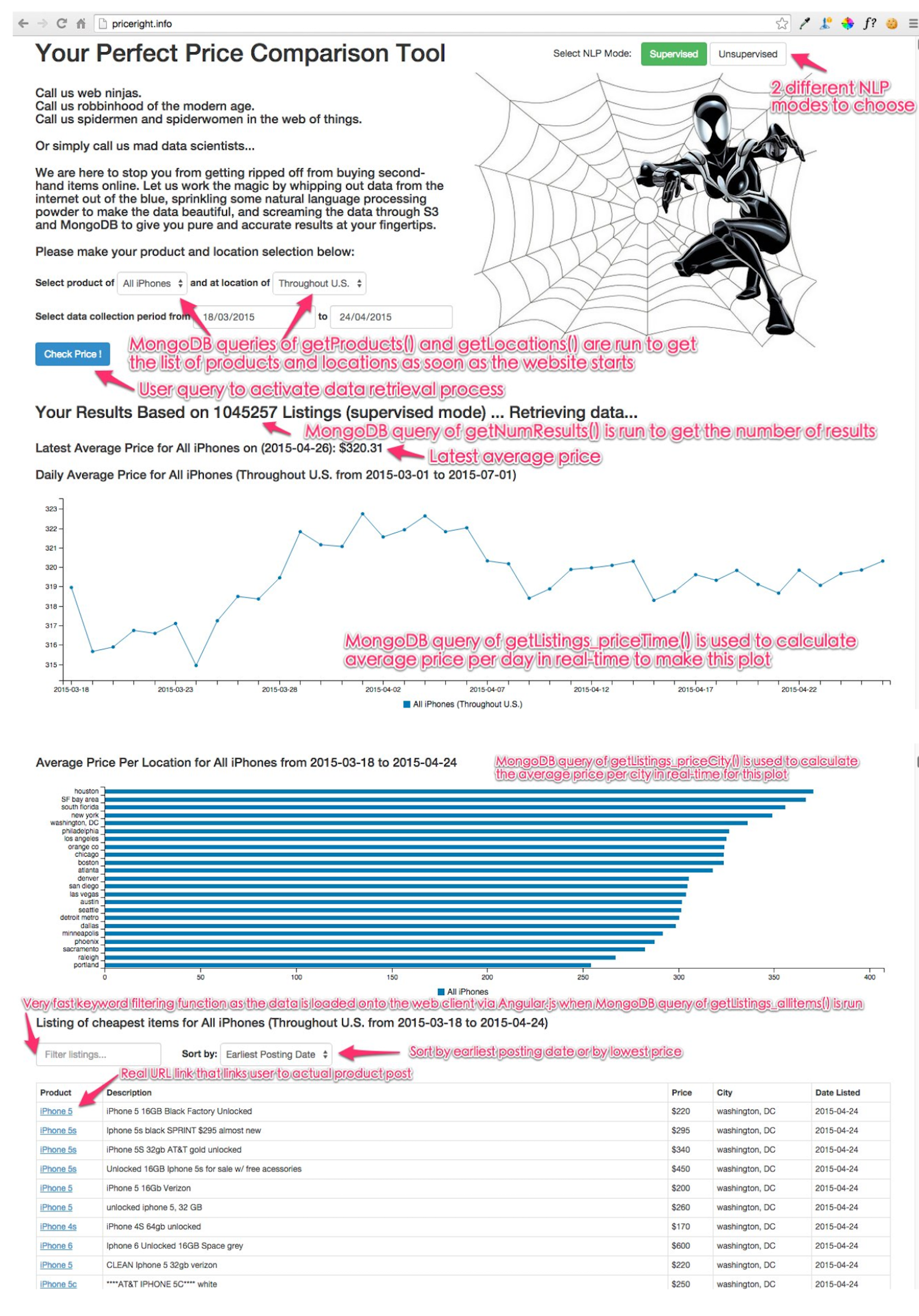
While the website is no longer live, the screenshot depicts our final product. The website allows a user to select an iPhone model, location, and date range, the website will then provide relevant results and price history in an easily digestible format.

In this Kaggle competition you are asked to predict the forest cover type (the predominant kind of tree cover) from strictly cartographic variables (as opposed to remotely sensed data). The actual forest cover type for a given 30 x 30 meter cell was determined from US Forest Service (USFS) Region 2 Resource Information System data. Independent variables were then derived from data obtained from the US Geological Survey and USFS. The data is in raw form (not scaled) and contains binary columns of data for qualitative independent variables such as wilderness areas and soil type.
This study area includes four wilderness areas located in the Roosevelt National Forest of northern Colorado. These areas represent forests with minimal human-caused disturbances, so that existing forest cover types are more a result of ecological processes rather than forest management practices.
Features included elevation, aspect, slope, distance to nearest surface water features, distance to nearest wildfire ignition points, hillshade, wilderness area, and soil type. The training data held an even split across all 7 cover types, whereas the test data was heavily skewed toward types 1 and 2. For this reason, we weighted observations (i.e. types 1 and 2 were more important) to account for the skewed test data.
Feature engineering was a key aspect of this project. Based on data visualization, forestry research, and intuition, we engineered several new features including distance to fire versus water, Euclidean distance to water, total energy based on hillshade, as well as several other comparative measures. The engineered features helped amplify variation between classes
We tested several classifiers including K-Nearest Neighbors, Support Vector Machines, and Logistic Regression, but ultimately used a variation of Random Forests known as Extra Trees as our final classifier. The classifier resulted in an accuracy of 84.03% and a Kaggle rank of 163.
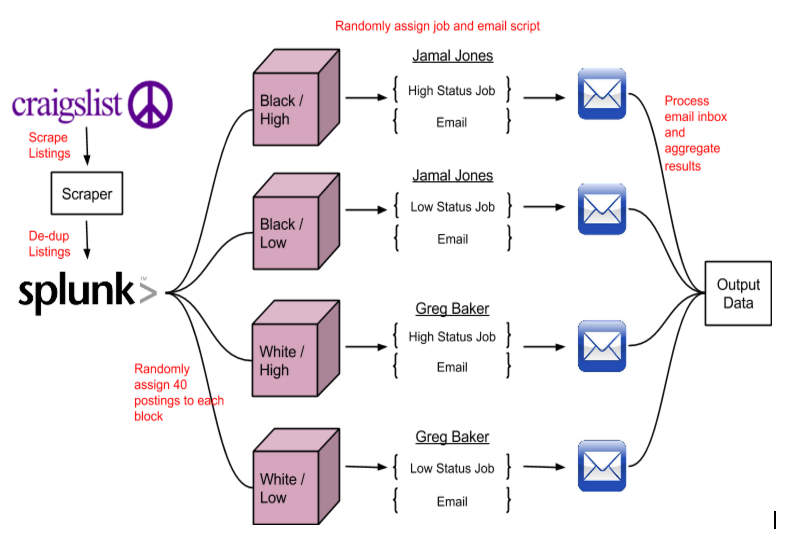
This experiment studies discrimination in the U.S. rental housing market by analyzing response rates to Craigslist housing inquiries. The study utilizes a 2x2 factorial design to measure the prevalence of racial and/or social status discrimination. Racial discrimination was tested by replying to Craigslist advertisements with either a “white-sounding” name (Greg Baker) or a “black-sounding” name (Jamal Jones) while social status discrimination was tested by varying the e-mail respondent’s job. The experiment was conducted on 800 Craigslist postings across five U.S. markets: Chicago, Cleveland, New York, Raleigh, and San Jose.
The experiment was a 2x2 factorial audit design, measuring the discriminatory effect of race and social status on the subjects. The subjects were landlords advertising their rental housing on Craigslist. The treatment was administered by sending email responses to the housing listing. Our main treatment of interest, the race of the respondent, was operationalized by the use of one black-sounding name, Jamal Jones, and one white-sounding name, Greg Baker. Our secondary treatment, social status, was administered via a profession mentioned in the email sent to the landlords. We used a binary outcome variable set to 1 in the event of a response to our automated inquiry and 0 for no response.
Craigslist advertisements were scraped using the Python library Scrapy, data was de-duped using Splunk, automated emails were generated against a randomized sample from each city, and results were aggregated with another Python script. The statistical analysis was conducted in R. A sample email is shown below.
I'm writing to inquire about your ad on Craigslist. I recently finished [graduate school/school] and took a job as [high job/low job] and I am looking for a place to live.
If the apartment is still available, I would like to schedule a showing for next week.
Thanks, [Greg Baker/Jamal Jones]
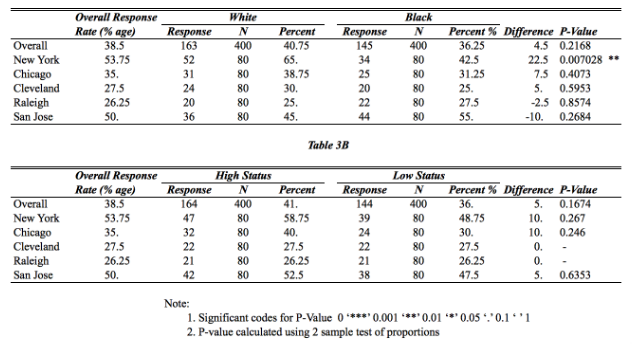
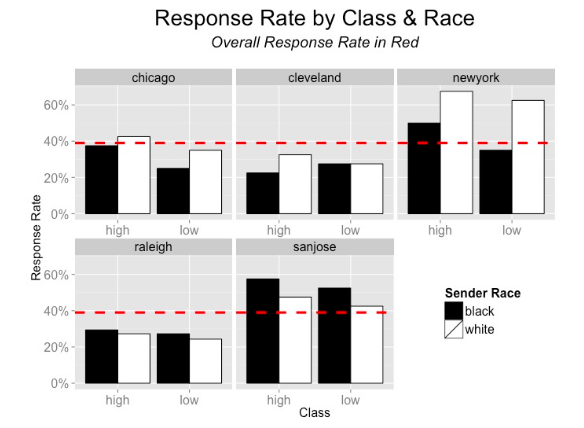
We did not find racial discrimination across the five housing markets, although the New York market did show discrimination with statistical significance. Additionally, we found some differences across social status when we controlled for rental price. This result indicates that landlords may base their decision to respond more on the social status of the applicant than on their race.
A more detailed description coming soon...